
Advisory: Be careful of what you read on social media. The algorithms used by these platforms have no regard for Biblical truth. They target your emotions to keep you engaged on their site so their advertisers can drop more ads. These platforms exist to enrich their stockholders. Consider God’s promise to Believers in James 1:5, “If any of you lacks wisdom, you should ask God, who gives generously to all without finding fault, and it will be given to you.”
Featured Story
**Imagine a world where Google has no secrets, where [all search engines play fair](https://searchenginewatch.com/2016/02/25/say-goodbye-to-google-14-alternative-search-engines/), and where SEO doesn’t have to be synonymous with “page one.” Sound like a fairy tale?**
The Internet is often cast as the great democratizer, and Google its noble gate-keeper. There’s no doubt that search engines help us easily navigate the web, but we have to remember that Google is a corporation, not a public service.
Our faith in its wisdom and guidance is based on little more than a carefully planned PR scheme. Behind that curtain, few of us really have any idea what’s going on. That kind of blind trust may be dangerous for content creators and consumers alike, both in terms of what we see and what we get.
In a recent column for [U.S. News & World Report](https://www.usnews.com/opinion/articles/2016-06-22/google-is-the-worlds-biggest-censor-and-its-power-must-be-regulated%E2%80%9D), artificial intelligence expert Dr. Robert Epstein detailed 10 different ways Google uses blacklists to censor the Internet. Some of them seem perfectly within reason – noble, even: banning weapons sales through its shopping service, for instance, or [blocking payday loan sharks](https://searchenginewatch.com/2016/05/16/google-bans-payday-loan-ppc-but-who-benefits/) from AdWords.
Few are going to argue with these measures. In fact, it’s nice to see a little corporate responsibility every once in awhile.
At the same time, though, how can we know when and where to draw the line? At what point does “corporate responsibility” become a catch-all phrase for “Google does what Google wants”?

The point Epstein makes is that with virtually every case of good Samaritan censorship practiced by the “do no evil” company, similar tactics have been used to justify some pretty blatant power grabs or downright bullying.
When media sources in Spain began demanding that aggregators pay fees for content, for example, Google News simply pulled out of the country altogether, and Spanish-based digital news sources have taken a serious hit since.
Consider too, the case of E-Ventures Worldwide, an SEO service website that had all 365 pages of its site blacklisted from search engine results because Google deemed them “pure spam.”
True, these revelations are not shocking for people who deal in SEO. Our line of work more or less entails tracking and following every algorithm-scented footprint or bit of guano we can find that might lead us to the keys of Google’s ranking systems, even while we live in constant fear of punishment from its all-knowing servers.
It comes as no surprise that Google harbors a tremendous power to influence, say, the results of a certain upcoming political election, or even to sway public opinion on the latest Taylor Swift/Kanye West escapade. The question is – and it’s a contentious one – where does it all end?
At what point (and sooner or later, there must come a point) will the authorities and powers-that-be have to reign in Google’s master controls over internet content and searchability?
After all, the FCC’s net neutrality ruling last year made internet service practically a public utility – in regulation, if not in name. And after broadband service providers, no one has more influence and control over the flow of the web than Google does.
“If Google were just another mom-and-pop shop with a sign saying ‘we reserve the right to refuse service to anyone’, that would be one thing,” Epstein writes. “But as the golden gateway to all knowledge, Google has rapidly become an essential in people’s lives – nearly as essential as air or water. We don’t let public utilities make arbitrary and secretive decisions about denying people services; we shouldn’t let Google do so either.”

Google Censorship – How It Works
An anticensorware investigation by Seth Finkelstein
Abstract: This report describes the system by which results in the Google search engine are suppressed.
Google Exclusion, introduction
Google is arguably the world’s most popular search engine. However, contrary perhaps to a naive impression, in some cases the results of a search are affected by various government-related factors. That is, search results which may otherwise be shown, are deliberately excluded. The suppression may be local to a country, or global to all Google results.
This removal of results was first documented in a report Localized Google search result exclusions by Benjamin Edelman and Jonathan Zittrain , which investigated certain web material banned in various countries. Later, this author Seth Finkelstein discussed a global removal arising from intimidation generated from the United Kingdom town of Chester, in Chester’s Guide to Molesting Google .
My discussion here is not meant to criticize Google’s behavior in any way. Much of it is in reaction to government law or government-backed pressure, where accommodation is an understandable reaction if nothing else. Rather, documenting and explaining what happens, can inform public understanding, and lead to more informed resistance against the distortion of search results created by censorship campaigns.
How it works
A Google search is not simply a raw dump of a database query to the user’s screen. The retrieval of the data is just one step. There is much post-processing afterwards, in terms of presentation and customization.
When Google “removes” material, often it is still in the Google index itself. But the post-processing has removed it from any results shown to the user. This system can be applied, for quality reasons, to remove sites which “spam” the search engine. And that is, by volume, certainly the overwhelming application of the mechanism. But it can also be directed against sites which have been prohibited for government-based reasons.
Sometimes the fact that the “removed” material is still in the index can be inferred.
Global censorship
For the case of Chester , which concerned a single “removed” page, the internal indexing of the target page could be established by comparison with a search for the same material on another search engine.
Consider a Google search for the word “lesbian” on the site torkyarkisto.marhost.com . It returns a page titled “The Kurt Cobain Quiz”, with a count of
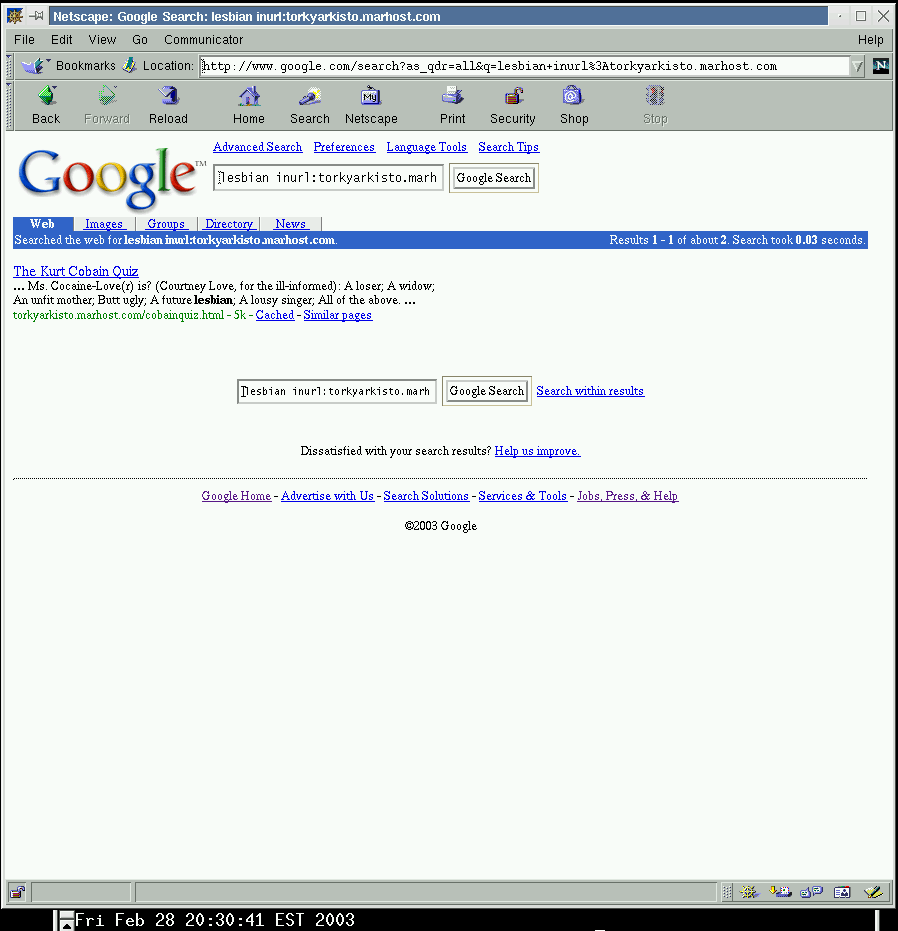{kind=link}
Results 1 - 1 of about 2
The “about” qualifier there represents many factors, but sometimes encompasses blacklisted pages. This can be seen here by comparing to an AltaVista search for the word “lesbian” on the site torkyarkisto.marhost.com
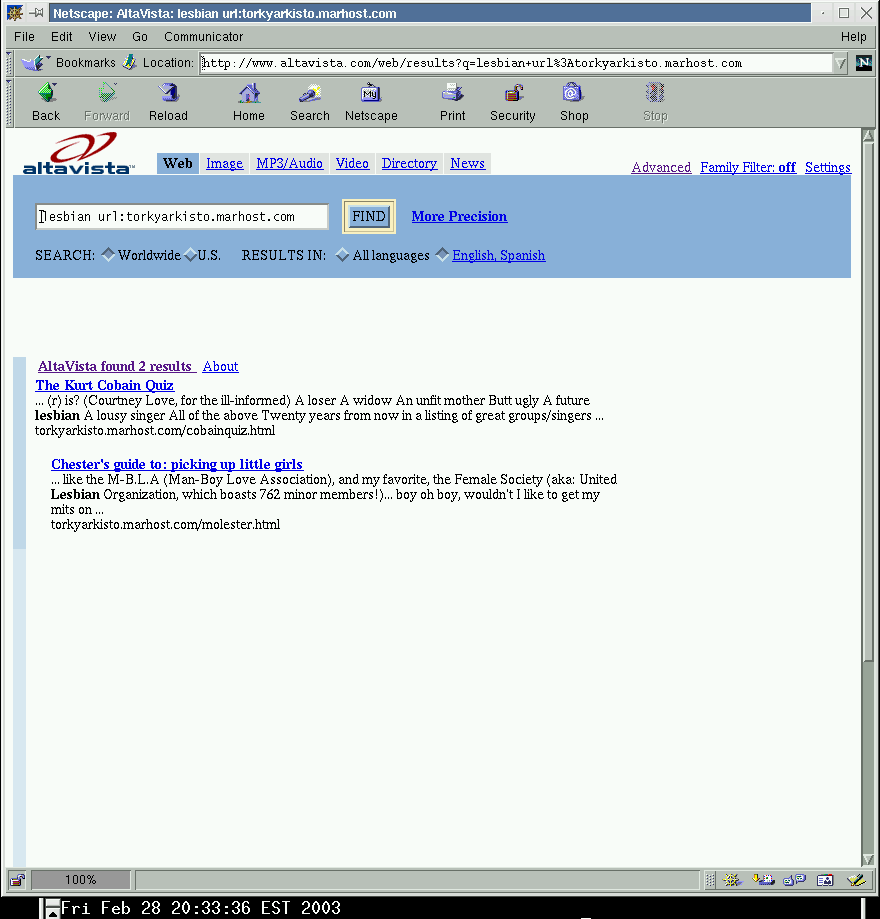{kind=link}
There are two pages visible in that case, the “Quiz” page, and the “Chester” page which caused all the trouble in the first place.
Since we know the “Chester” page was once in the Google index, it must be the other page referred to in “about 2“. QED.
Local censorship
In this situation, comparing results from the different Country Google searches, is often revealing. The tests are often best done using the “allinurl:” syntax of Google, which searches for URLs which have the given components (note the separate components can appear anywhere in the URL, so “allinurl:stormfront.org” is “stormfront” and “org” in the URL, not just the string “stormfront.org” as might be naively thought). Stormfront.org is a notorious racist site, often banned in various contexts.
Consider the following US search:
http://www.google.com/search?num=100&hl=en&q=allinurl%3Astormfront.org
This returned: Results 1 - 27 of about 50,700.
{kind=link}
Now compare with the German counterpart (Google.DE):
http://www.google.de/search?num=100&hl=en&q=allinurl%3Astormfront.org
This returned: Results 1 - 9 about 50,700.
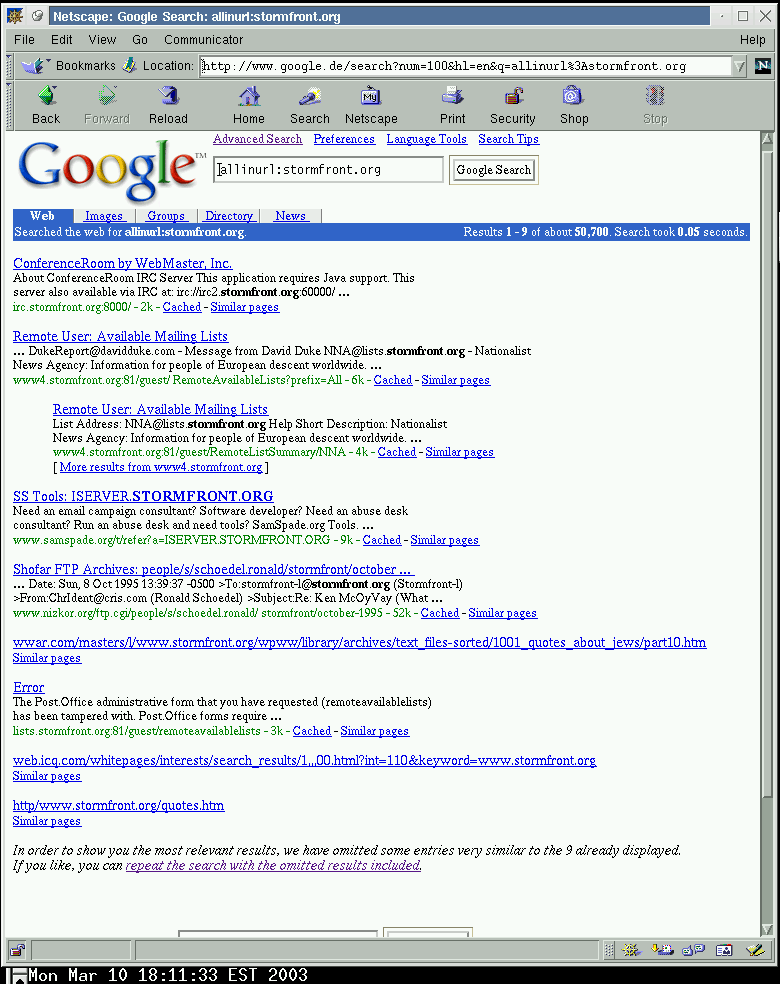{kind=link}
Immediate observation: The rightmost (total) number is identical. So identical results are in the Google database. It’s simply not displaying them. How is it determining which domain results to display?
Note the hosts of which “stormfront.org” URLs are visible on the German page:
irc.stormfront.org:8000/
www4.stormfront.org:81/
lists.stormfront.org:81/
What do these all have in common?
They all have a port number after the host name.
The exclusion pattern obviously isn’t matching the “:number” part of the URL.
It’s matching a pattern of “*.stormfront.org/” in the host, as in the following which are displayed the US search, but not the German search.
www.stormfront.org/
kids.stormfront.org/
women.stormfront.org/
nna.stormfront.org/
www4.stormfront.org/
Even more interesting, the German page has a broken URL listed at the bottom: http/www.stormfront.org/quotes.htm . That’s not a valid URL, so it seems to escape the host check.
Thus, the suppression again appears to be implemented as a post-processing step using very simple patterns of prohibited results.
The same behavior is observed in a German “stormfront.org” images search
This returned: Results 1 - 6 about 1,410.
Versus a US “stormfront.org” images search
This returned: Results 1 - 18 about 1,410.
(note identical right-hand numbers, and hosts matching “*.stormfront.org/” pattern are suppressed in the German results)
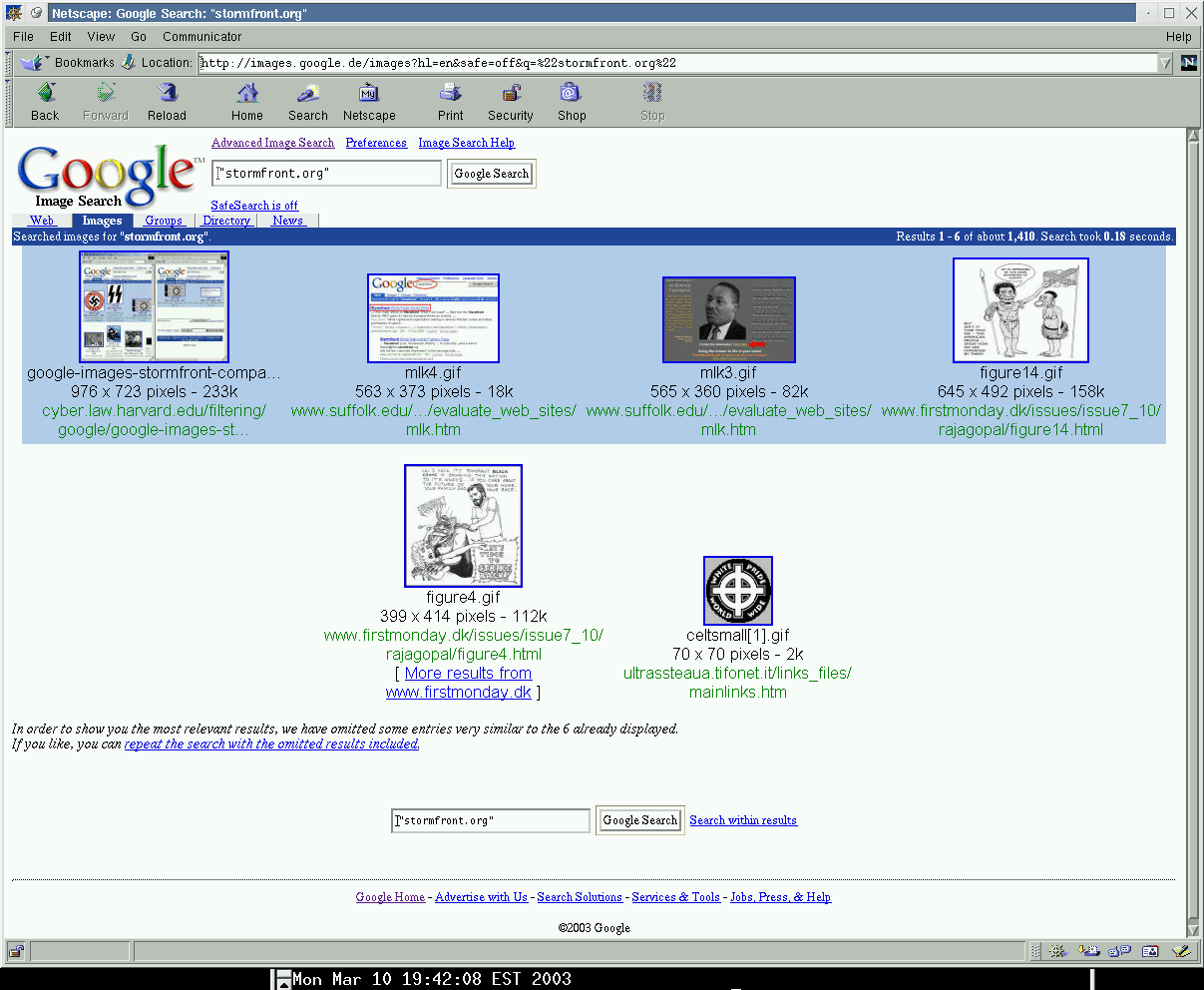{kind=link}
{kind=link}
And also in a German “stormfront.org” directory search
This returned: Results 1 - 8 about 15.
Versus a US “stormfront.org” directory search
This returned: Results 1 - 10 about 15.
(note again identical right-hand numbers, and hosts matching “*.stormfront.org/” pattern are suppressed in the German results)
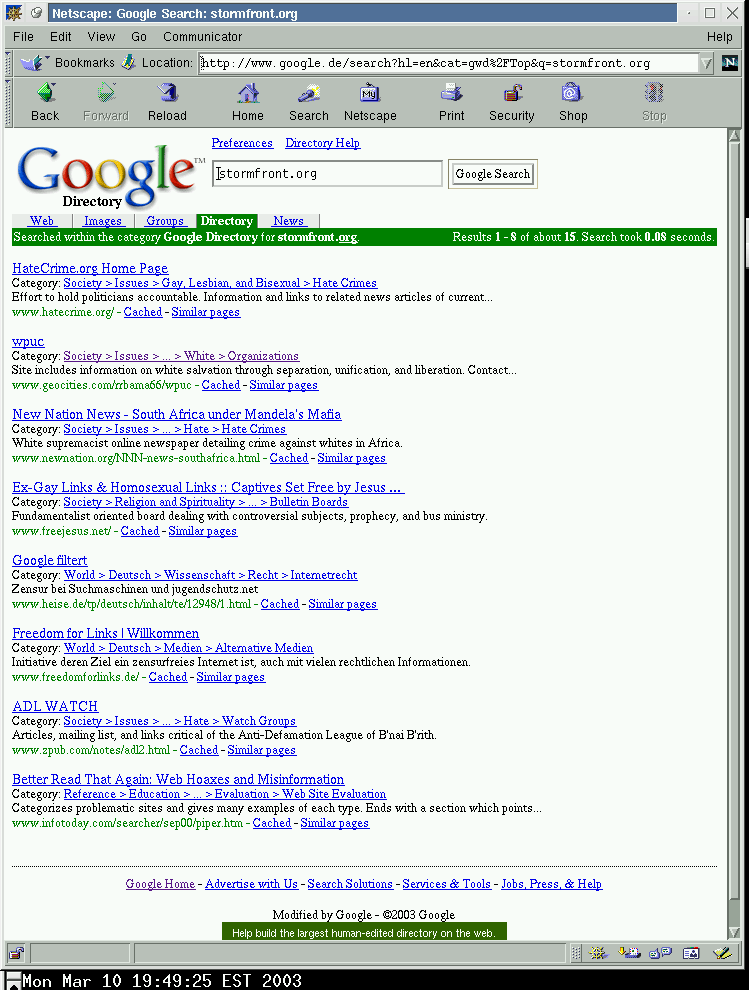{kind=link}
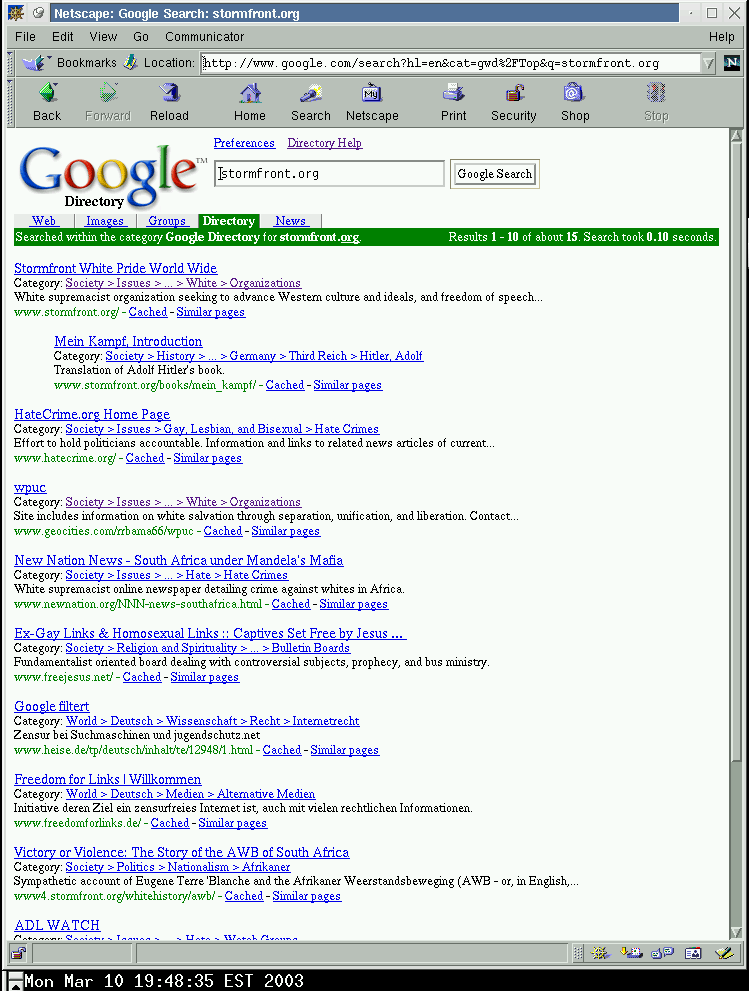{kind=link}
Conclusion
Contrary to earlier utopian theories of the Internet, it takes very little effort for governments to cause certain information simply to vanish for a huge number of people.
http://sethf.com/anticensorware/general/google-censorship.php

All Original Content Copyright ©2017 hnewswire.com All Rights Reserved.


Tagged In
Newsletter
Must Read




Other Sources

Latest News

Watchman: Truth-Tellers Are Becoming a Major Target, and Evildoers Want To Sanction Tucker Carlson for His Interview With Putin. The Truth Will Come Out, Very Soon!
By SRH, Watchman: Truth-tellers are becoming a major target, and extremists want to sanction Tucker Carlson for his interview with Putin. As part of a…
Read More
SRH: Crime Publishing Truth’s Julian Assange Is the Watchman. That’s Unacceptable for Most Governments Today. U.S., U.K., et al.
Please Help Donate GiveSendGo By SRH, Julian Assange, of Crime Publishing Truth, serves as the watchman. That is unacceptable to most regimes today. US, UK,…
Read More
Watchman: Google, DuckDuckGo, and Bing Have Hidden the Truth, and the People Are Misled and Forever Harmed!
Have nothing to do with the fruitless deeds of darkness, but rather expose them. (Ephesians 5:11) By SRH, Not only is Google, Inc. the largest…
Read More
Watchman:The Further a Society Drifts From the Truth, the Stronger the Delusion Will Take Its Place. “It Is Better to Be Divided by Truth Than to Be United in Error. It Is Better to Speak the Truth That Hurts and Then Heals, Than Falsehood That Comforts and Then Kills–The New World Order Will KILL!
By SRH, As U.S. Founding Father Benjamin Franklin said, “Man will ultimately be governed by God or by tyrants.” When a culture abuses its democratic…
Read More
THE MSM HAS LED THE AMERICAN PEOPLE DOWN A PATH OF DARKNESS INTENTIONALLY
Darkness and light are metaphors for evil and good. If anyone sees an angel of light, it will automatically seem to be a good…
Read More

We make every effort to acknowledge sources used in our news articles. In a few cases, the sources were lost due to a technological glitch. If you believe we have not given sufficient credit for your source material, please contact us, and we will be more than happy to link to your article.